
書き込み性能がスケールアウトする Amazon Aurora PostgreSQL Limitless Database が一般提供となったので、実際に機能して試してみました!
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
ウィスキー、シガー、パイプをこよなく愛する大栗です。
昨年の AWS re:Invent 2023 で発表されていた、書き込み性能をスケールできる Amazon Aurora PostgreSQL Limitless Database が一般提供となりました!早速レポートします。
- What's New - Amazon Aurora PostgreSQL Limitless Database is now generally available
- AWS News Blog - Amazon Aurora PostgreSQL Limitless Database is now generally available
Amazon Aurora PostgreSQL Limitless Database
Amazon Aurora PostgreSQL Limitless Database(以降 Limitless Database) は AWS re:Invent 2023 で発表されていた書き込み性能をスケールできる Aurora です。
Limitless Database はデータベースのシャーディング構成をマネージドな構成で提供することで、既存のような読み込み性能のスケールだけでなく、書き込み性能のスケールも行うためのデータベースです。複数ノード間にまたがるトランザクションなどもサポートして書き込み性能もスケールアウトするため、いわゆる NewSQL の一種と呼べると思います。
re:Invent 2023 での Limitless Database に関するブレイクアウトセッションの内容は以下のエントリをご覧ください。
Limitless Database は複数のデータベース ノードで構成される2階層アーキテクチャになっています。ルーターはデータベースの分散を管理してクライアントからの SQL 接続を受け入れて解析してシャードへ送信して、シャードはシャーディングされたテーブルのサブセットです。
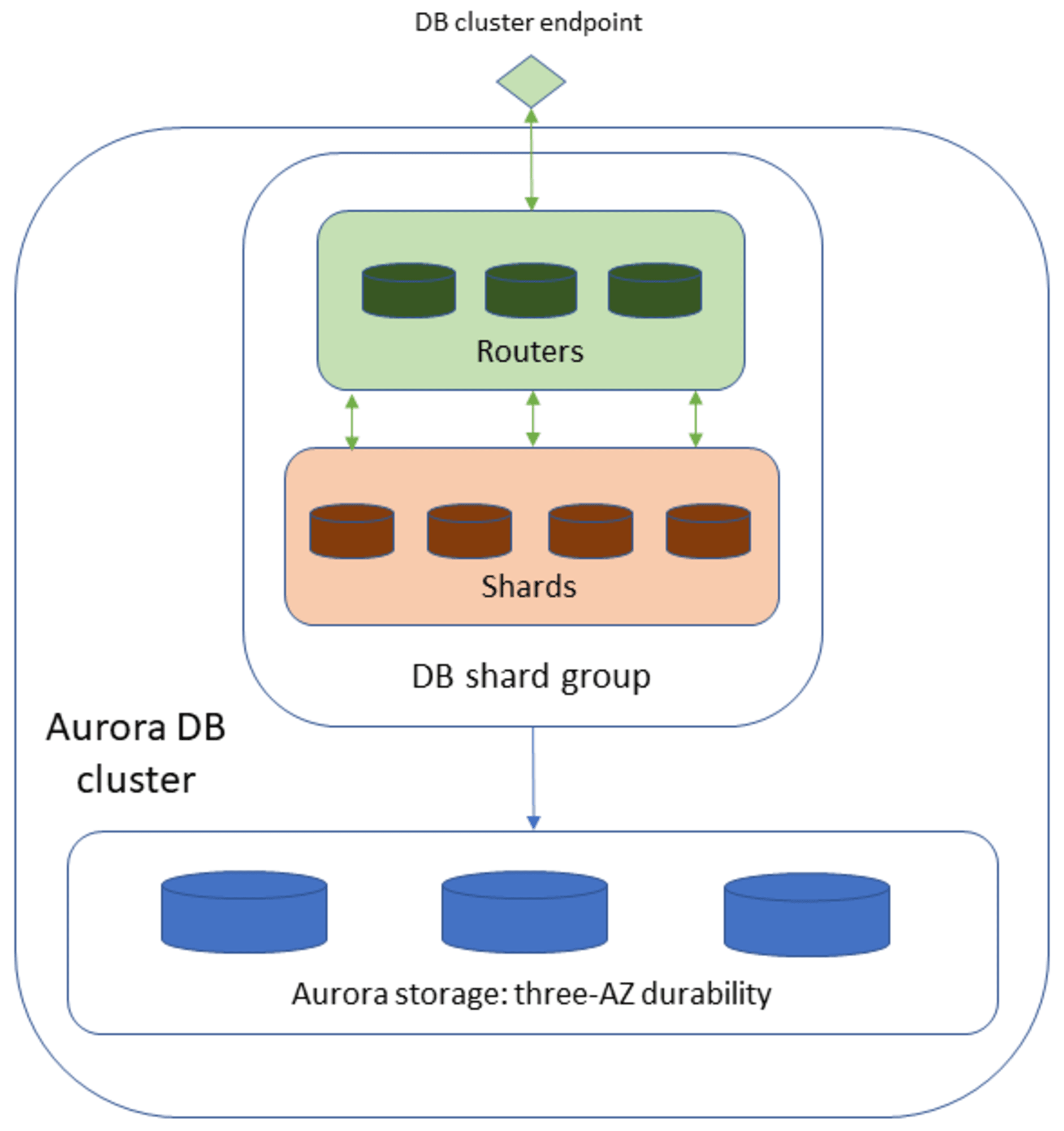
Limitless Database を実際に試した内容はエントリの後半です。
キーワード
Limitless Database では以下の重要なキーワードがあります。
- DB シャードグループ:Limitless Database のコンテナ
- ルーター:クライアントから SQL 接続を受け、SQL コマンドをシャードに送信して、システム全体の一貫性を維持し結果をクライアントへ返す
- シャード:シャードテーブルのサブセット、リファレンステーブルの完全なコピー、スタンダードテーブルを格納します
- シャードテーブル:データがシャード間で分割されたテーブル
- シャードキー:シャード間のパーティション分割を決定するためのシャードテーブル内のカラム
- 共存テーブル:同じシャードキーを共有し、明示的に共存として定義されている複数のシャードテーブルで、同じシャードキーのすべてのデータは同じシャードへ送信される
- リファレンステーブル:すべてのシャードにデータが完全にコピーされたテーブル
- スタンダードテーブル:Limitless Database の標準のテーブルタイプで、システムで内部的に選ばれたシャードの一つに保存されて、シャードテーブルやリファレンステーブルに変換できます
Limitless Database を使用可能なリージョン
現在利用可能なリージョンは以下のようになっています。
- アジアパシフィック (香港)
- アジアパシフィック (シンガポール)
- アジアパシフィック (シドニー)
- アジアパシフィック (東京)
- 欧州 (フランクフルト)
- 欧州 (アイルランド)
- 欧州 (ストックホルム)
- 米国東部 (バージニア北部)
- 米国東部 (オハイオ)
- 米国西部 (オレゴン)
Limitless Database の要件
Limitless Database には以下の要件[1]があります。
- Limitless Database は、Aurora I/O 最適化 DB クラスターのストレージ構成のみをサポートします
- Limitless Database は、専用の特別な Aurora PostgreSQL DB エンジン バージョン
16.4-limitlessを使用します - DB クラスターには、ライター DB インスタンスまたはリーダー DB インスタンスを含めることはできません
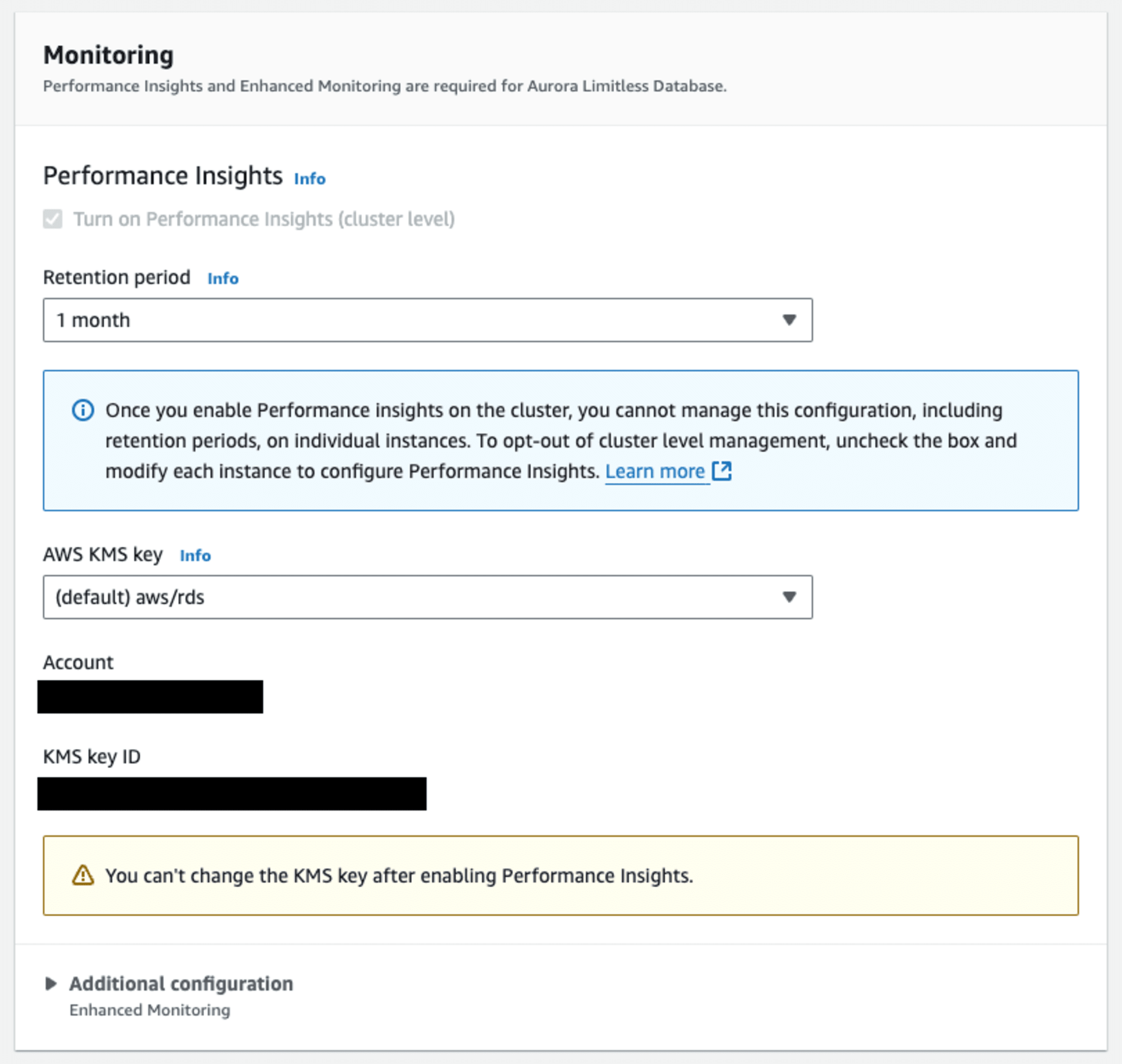
- 拡張モニタリングとパフォーマンス インサイトを使用する必要があります
- PostgreSQL ログを Amazon CloudWatch Logs にエクスポートする必要があります
Limitless Database に関する考慮事項
Limitless Database の DB シャードグループには、次の考慮事項[2]が適用されます。
- DB クラスターごとに 1 つの DB シャードグループのみを成できます
- リージョンごとに最大 5 つの DB シャードグループを作成できます
- シャードグループの最大容量は 16~6144 ACU に設定できます
- DB シャードグループの最大容量を変更しても、ルーターとシャードの数は変わりません
- ルータごとに 1 つの IP アドレスが必要で、DB シャードグループ内のシャードごとに最大 3 つの IP アドレスが必要です
- DB シャードグループをパブリックにアクセス可能にする場合は、VPC にインターネット ゲートウェイを設定してください
- SQL 関数を使用してシャードを分割やルーター追加を行います
- シャードのマージはサポートされていません
- 個々のシャードとルーターを削除することはできません
- テーブル行の値の変更を含め、シャードキーをいかなる方法でも変更 (UPDATE 操作など) することはできません
- 分離レベルは REPEATABLE READ、READ COMMITTED、READ UNCOMMITTED がサポートされています
- 一部の SQL コマンドはサポートされていません[3]
- すべての PostgreSQL 拡張機能がサポートされているわけではありません[4]
- シャードグループを作成するとき、または新しいシャードグループノード (シャードまたはルーター) を追加するとき、それらのノードは DB クラスターで使用可能な AZ の 1 つに作成されます
- コンピューティングの冗長化を「2 つのフェイルオーバーターゲットを使用したコンピューティングの冗長性」にする場合は、DB サブネット グループに少なくとも 3 つの AZ があることを確認してください
Limitless Database DB クラスターには、次の考慮事項[2:1]が適用されます。
- AWS 管理ポリシーを使用して、データベースとアプリケーションに対するアクセス許可をユーザーのユースケースに必要なアクセス許可に制限することが推奨されます
- Aurora PostgreSQL Limitless Database DB クラスターを作成するときは、DB シャードグループのスケーリング パラメータのみを設定します
- DB シャードグループを含む DB クラスターを停止または起動できません
- DB クラスターを削除する必要がある場合は、まず DB シャードグループを削除する必要があります
- Aurora PostgreSQL Limitless データベースはレプリケーション ソースにできません
Limitless Database でサポートされていない機能
以下の機能は Limitless Database でサポートされていません[4:1]。
- Active Directory (Kerberos) 認証
- Amazon DevOps Guru
- Amazon ElastiCache
- Amazon RDS ブルー/グリーンデプロイ
- Amazon RDS Proxy
- Aurora Auto Scaling (DB クラスターにリーダーインスタンスを自動的に追加する)
- Aurora Global Database
- Aurora 機械学習
- Aurora recommendations
- Aurora Serverless v1
- AWS Lambda integration
- AWS Secrets Manager
- Babelfish for Aurora PostgreSQL
- DB クラスタークローン
- データベースアクティビティストリーム
- リードレプリカ
Limitless Database の料金
データベースインスタンスの料金設定
Limitless Database は Aurora Serverless v2 と同じ料金体系となっています。ただし、Limitless Database は Aurora I/O 最適化 DB クラスターのストレージ構成のみをサポートします。そのため、東京リージョンでは 1 ACU 時間あたり USD 0.26 となっています。
ただし Limitless Database は最小 16 ACU であるので
USD 0.26 * 16 ACU = USD 4.16
最小構成で 1 時間あたり USD 4.16(USD 1 を 153 円とすると 636.48 円)からで、「1 つのフェイルオーバーターゲットを使用したコンピューティングの冗長性」の場合は USD 8.32(1272.96 円)から、「2 つのフェイルオーバーターゲットを使用したコンピューティングの冗長性」の場合は USD 12.48(1909.44 円)からとなります。
データベースストレージの料金設定
Aurora I/O 最適化が前提であるため
USD 0.27/毎月の GB あたり
なっており I/O 料金はストレージ料金に含まれます。
やってみる
ここでは東京リージョンを前提とします。
Limitless Database の作成
RDS のデータベースを作成します。作成方法は 標準作成 を選択して、エンジンは Aurora (PostgreSQL Compatible) を選択します。
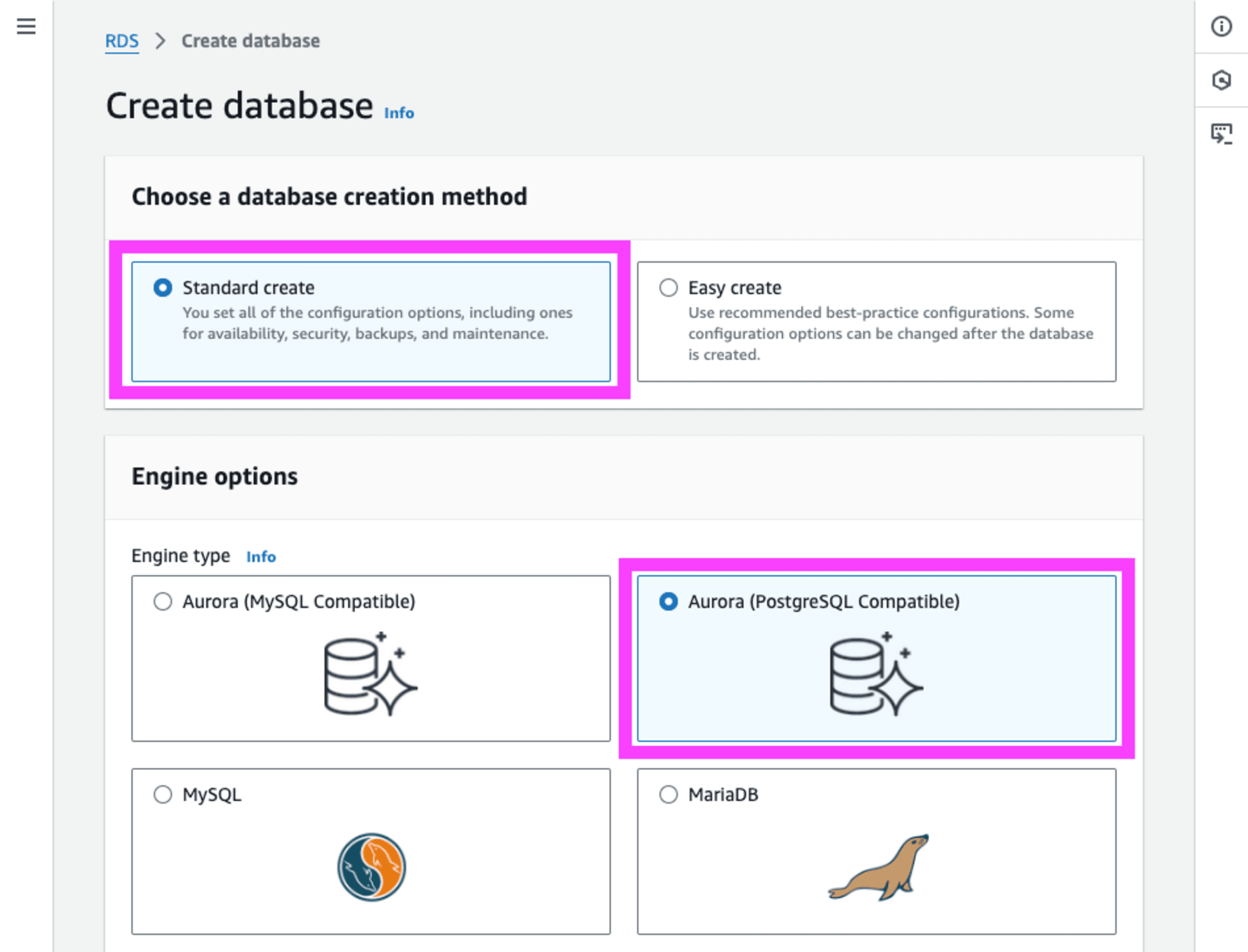
エンジンバージョンは Aurora PostgreSQL with Limitless Database (Compatible with PostgreSQL 16.4) を選択します。
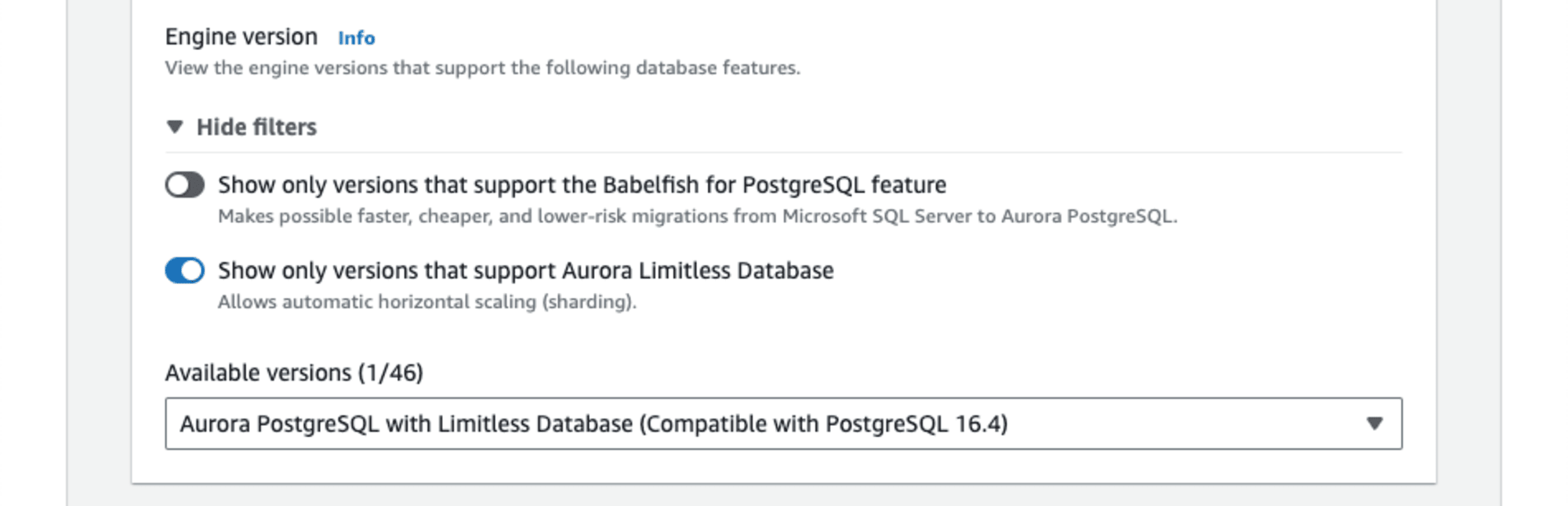
テンプレートは、ここでは 本番稼働用 を選択します。
DB クラスター識別子は任意、マスターユーザー名はここではデフォルト、認証情報管理はセルフマネージド(現在 Limitless Database は AWS Secrets Manager がサポートされていない)、パスワードを任意に入力します。
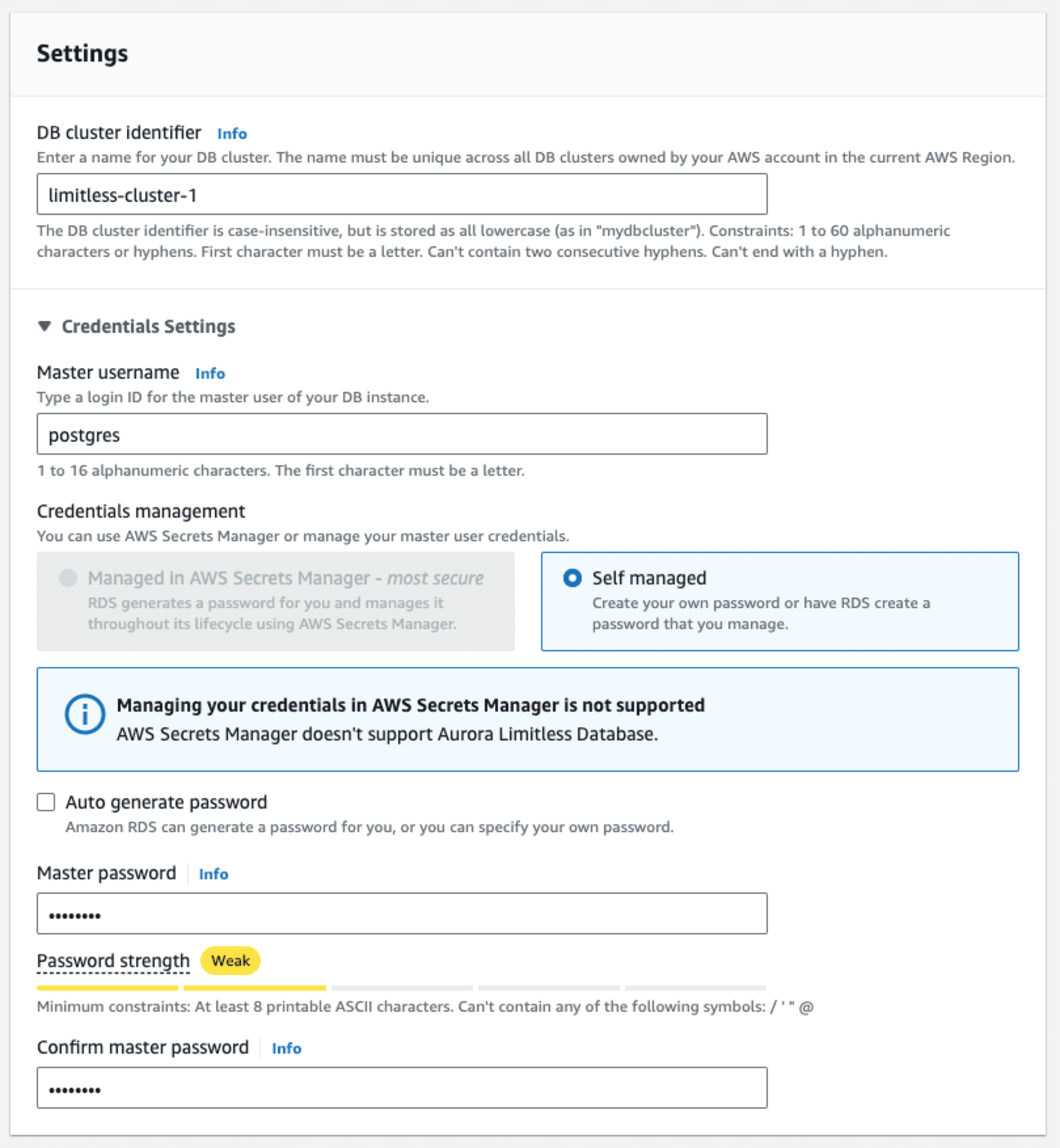
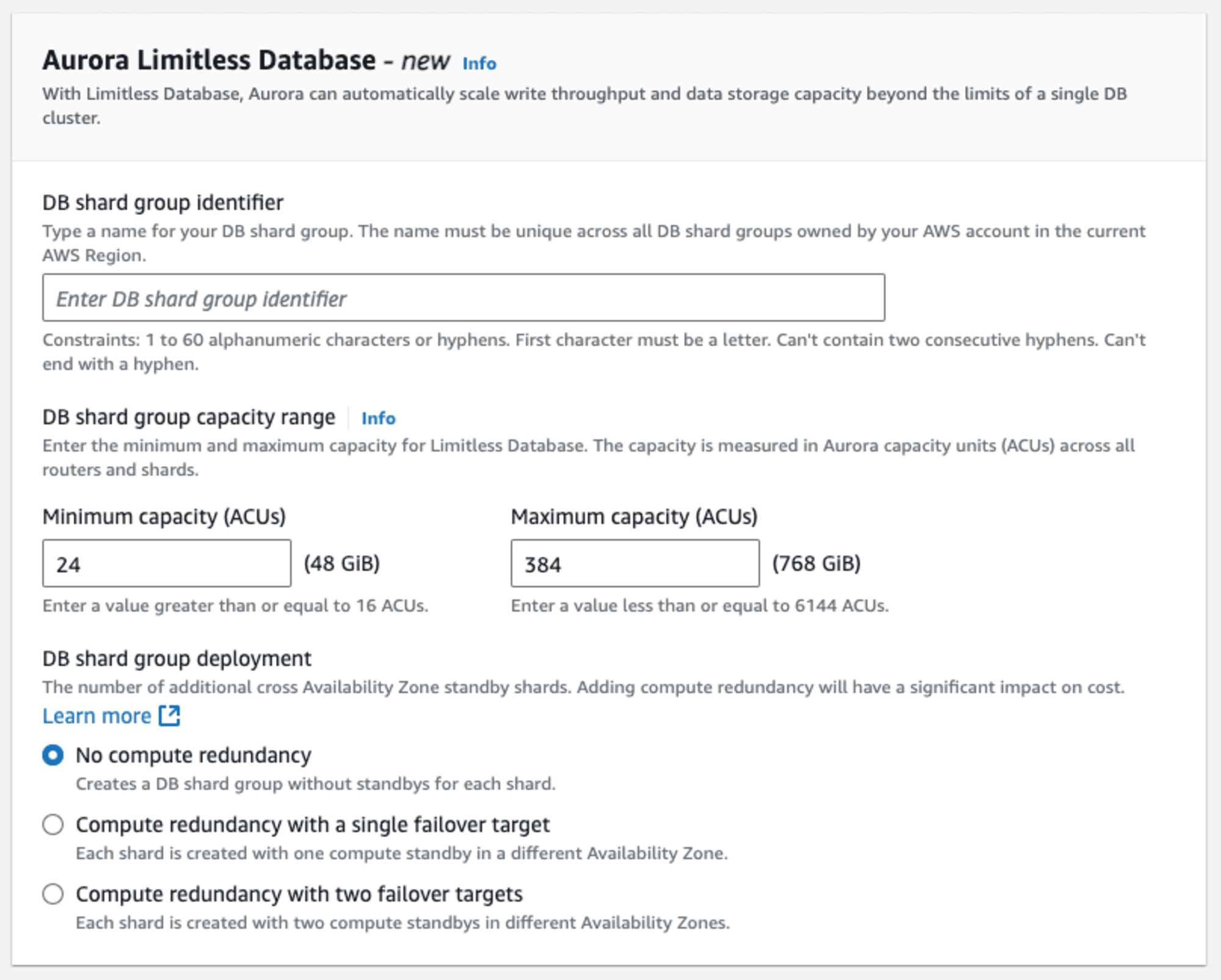
Limitless Database 特有の設定を行います。
DB シャードグループ識別子は任意に入力します。DB シャードグループのキャパシティ範囲は最小が 16 ACU 以上で最大が 6144 ACU 以下の値を設定します。DB シャードグループのデプロイは必要に応じて冗長性を設定しますが、ここでは「2 つのフェイルオーバーターゲットを使用したコンピューティングの冗長性」をしました。
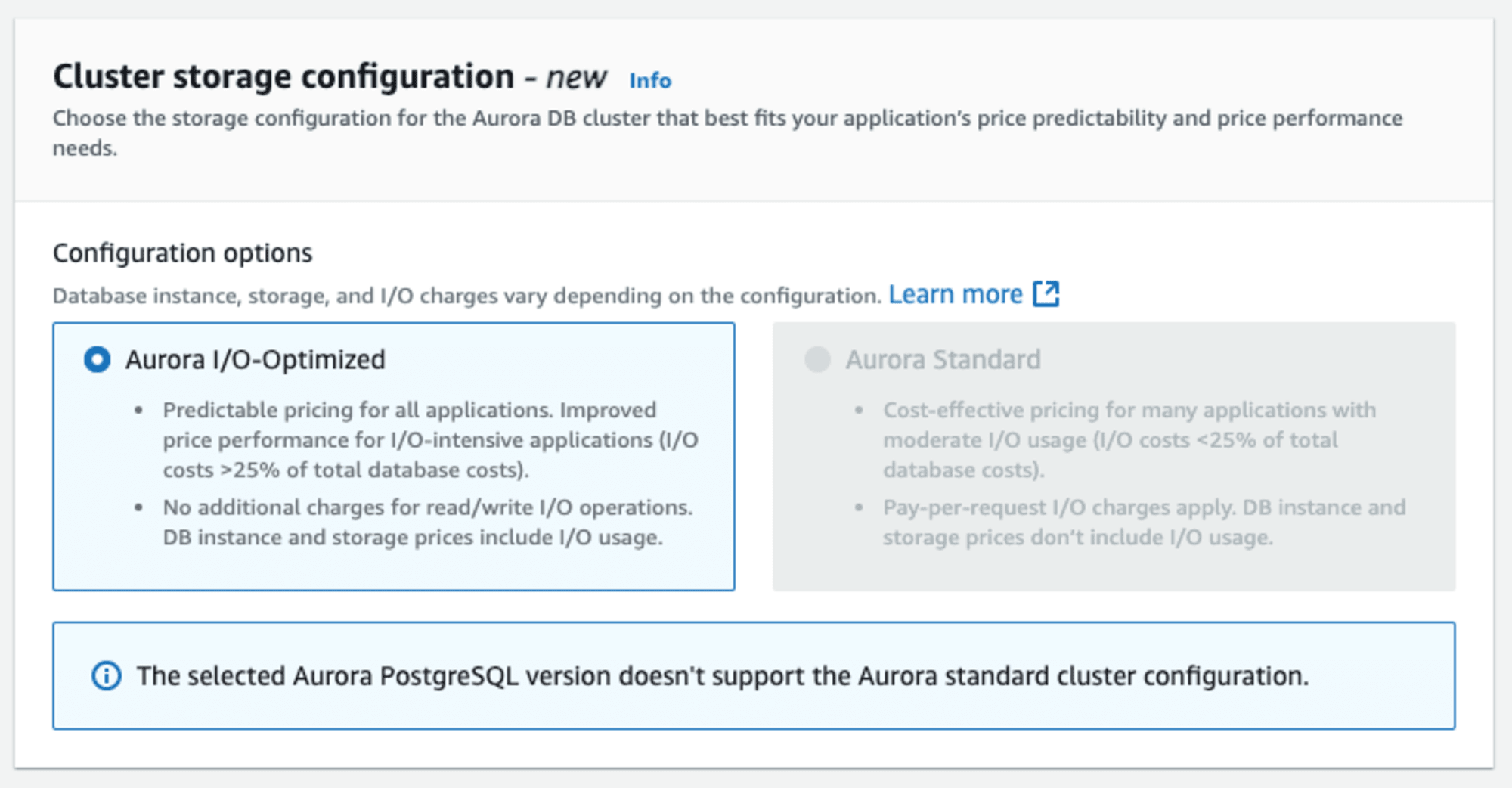
クラスターストレージ設定はAurora I/O 最適化を選択します。標準クラスター設定をサポートしていません。
接続の設定は任意に行います。「2 つのフェイルオーバーターゲットを使用したコンピューティングの冗長性」を設定している場合には、DB サブネットグループで 3 AZ が含まれているものを選択します。
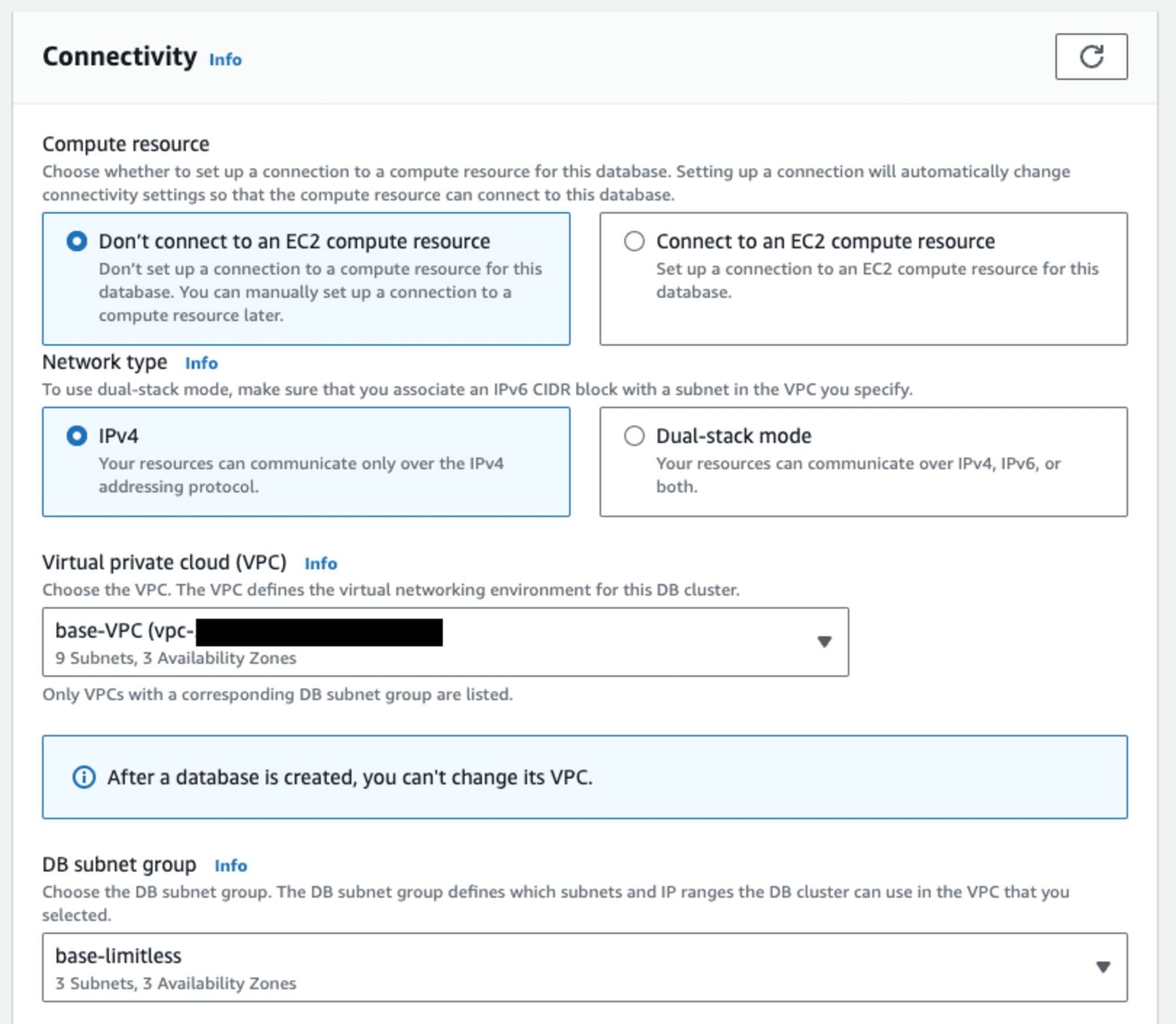
ここではパブリックアクセスはせず、VPC セキュリティグループで PostgreSQL アクセス用のものを選択します。RDS Proxy はサポートされていません。
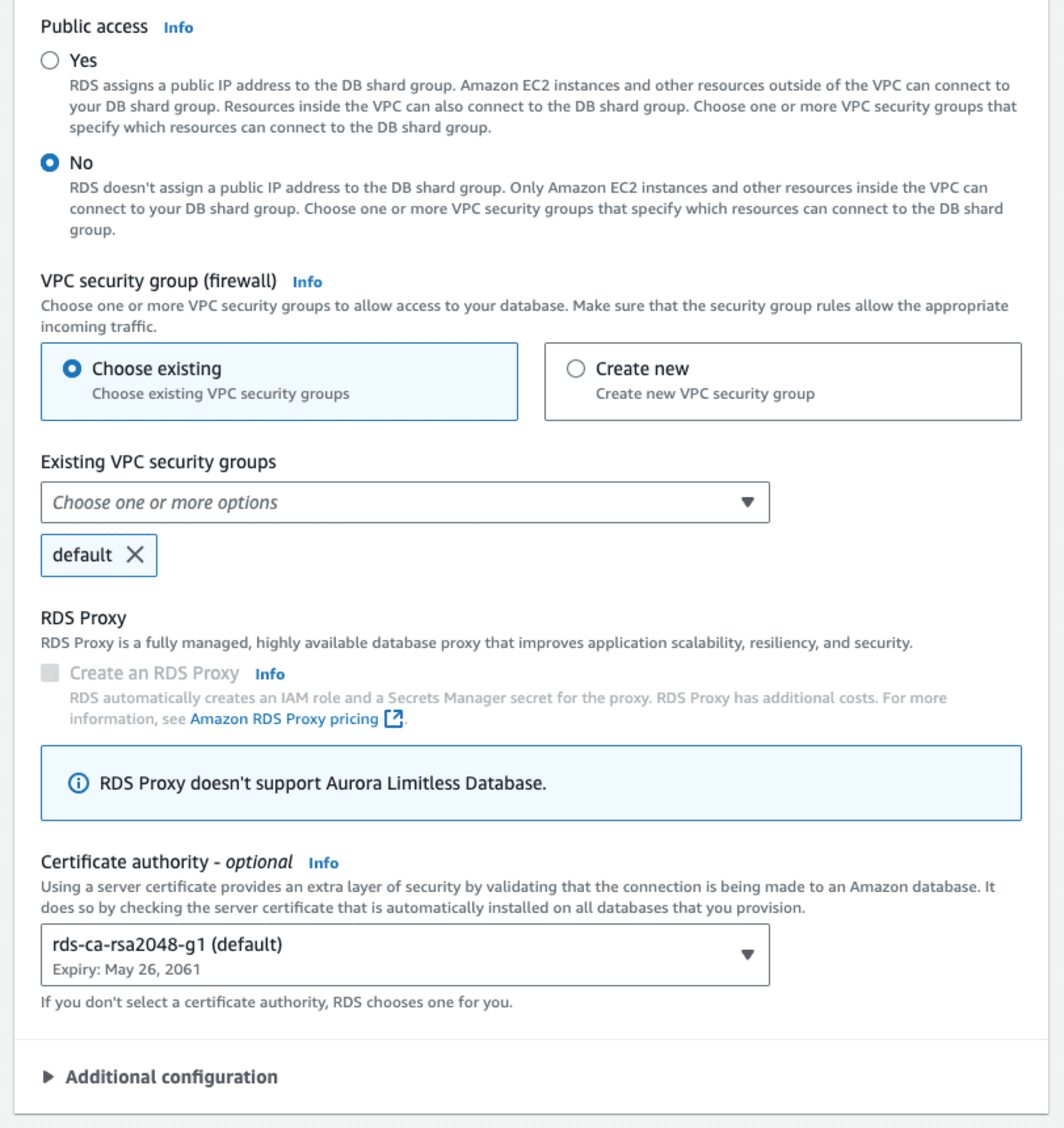
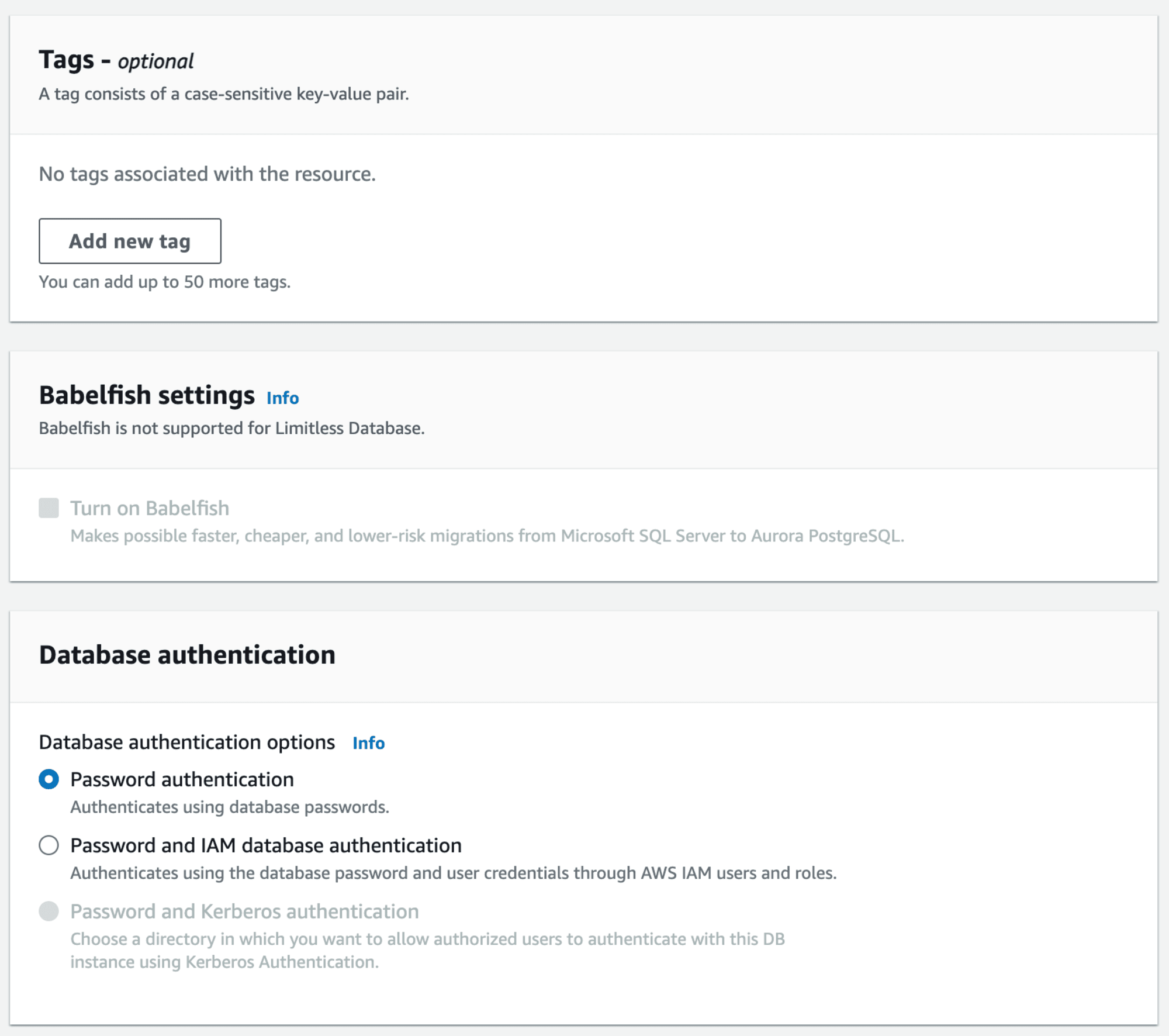
タグは任意に設定します。Babelfish はサポートされていません。データベース認証は Kerberos 認証がサポートされていないため「パスワード認証」か「パスワードと IAM データベース認証」を選択します。
モニタリングではパフォーマンスインサイトと拡張モニタリングが有効化され無効化できません。
データベースの作成 を実行します。
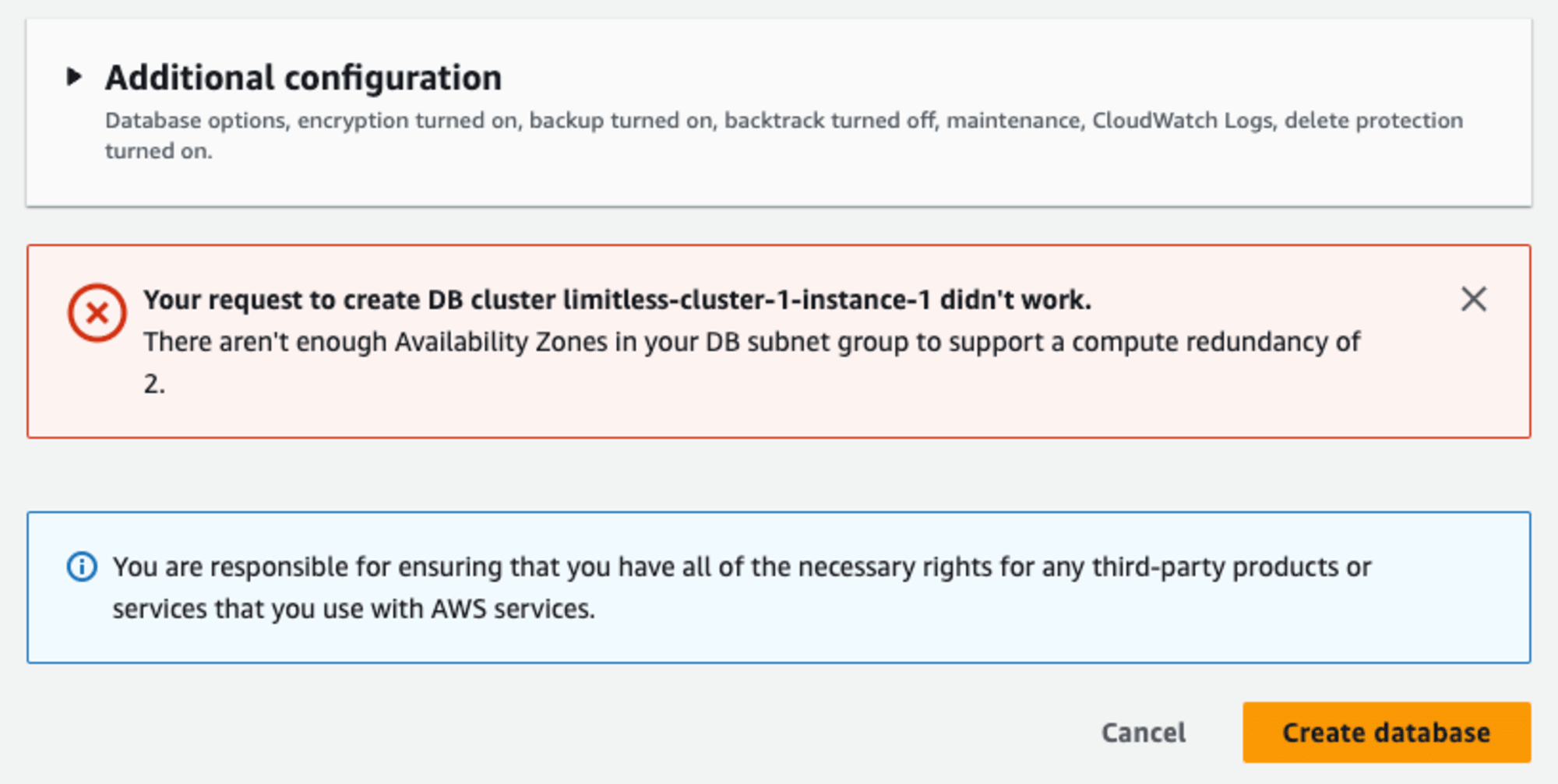
DB インスタンスの作成に失敗しました。DB サブネットグループで apne1-az1, apne1-az3, apne1-az4 のサブネットを選択していましたが、おそらく apne1-az3 を使用しているためと思われます。DB シャードグループのデプロイで「単一のフェイルオーバーターゲットを使用したコンピューティングの冗長性」を選択し直します。一旦作成された DB クラスターを削除してデータベースを再度作成します。
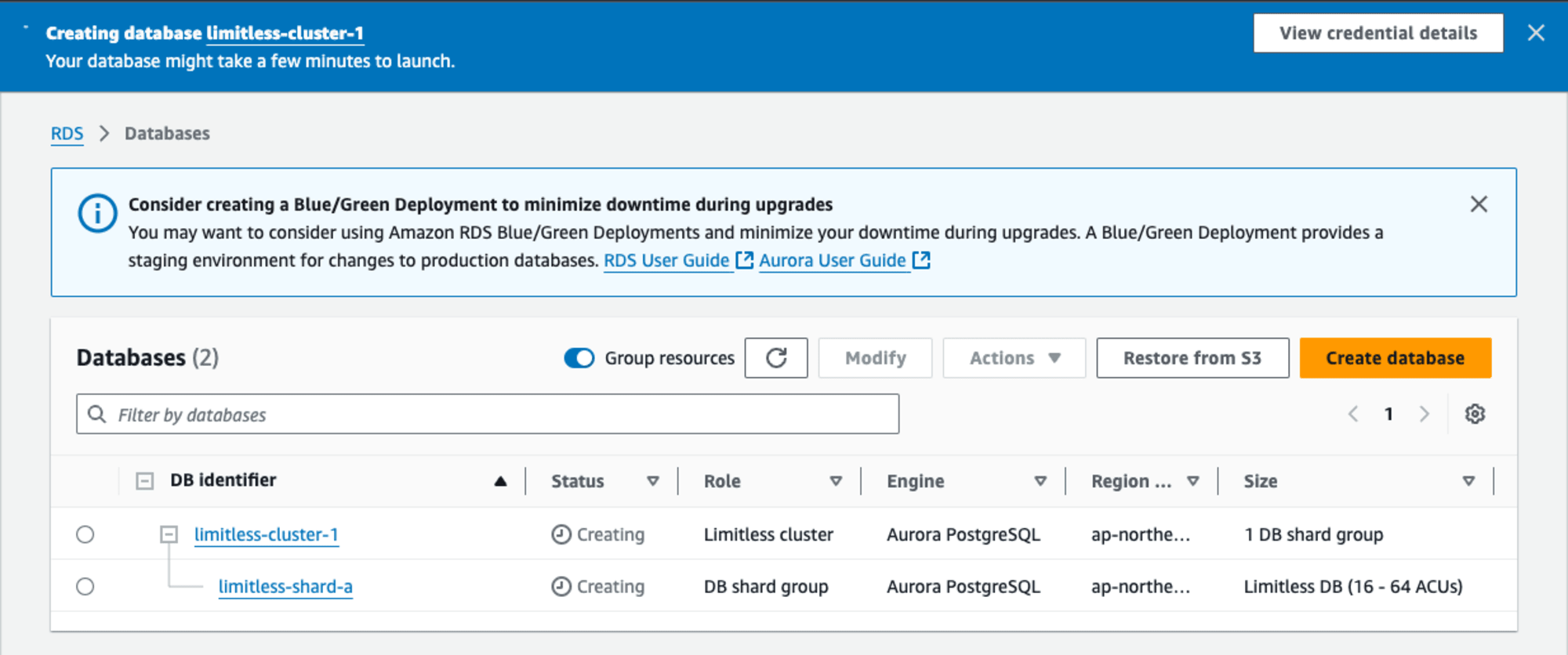
DB クラスターが作成されるまでしばらく(実績で100分以上)待ちます。
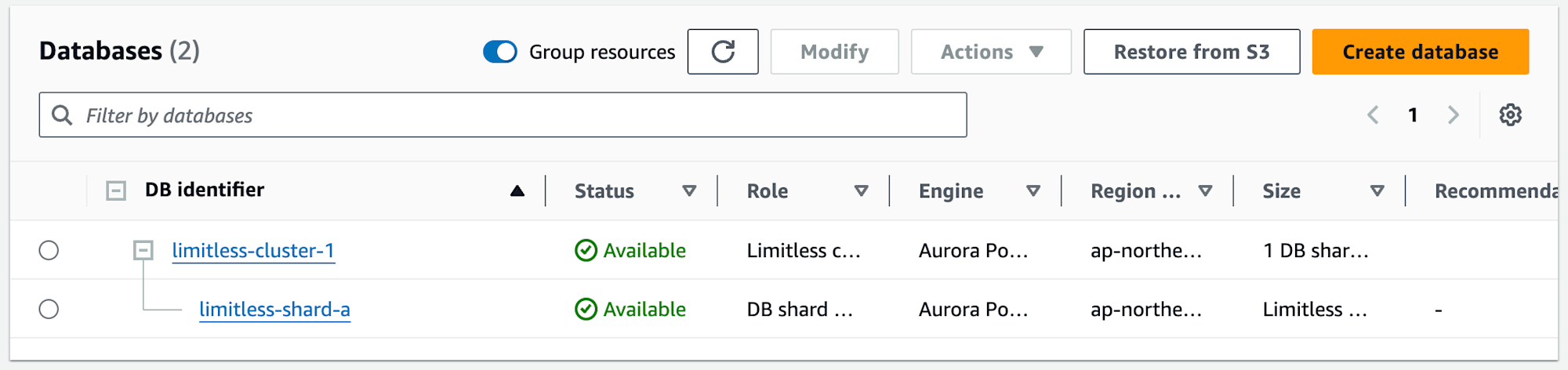
起動しました。
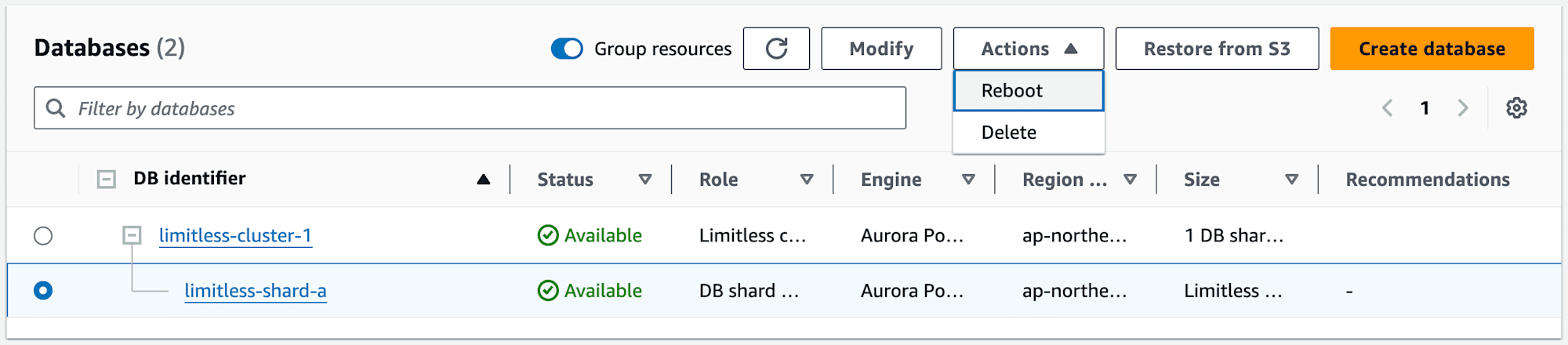
クラスターのアクションは以下の様になっています。
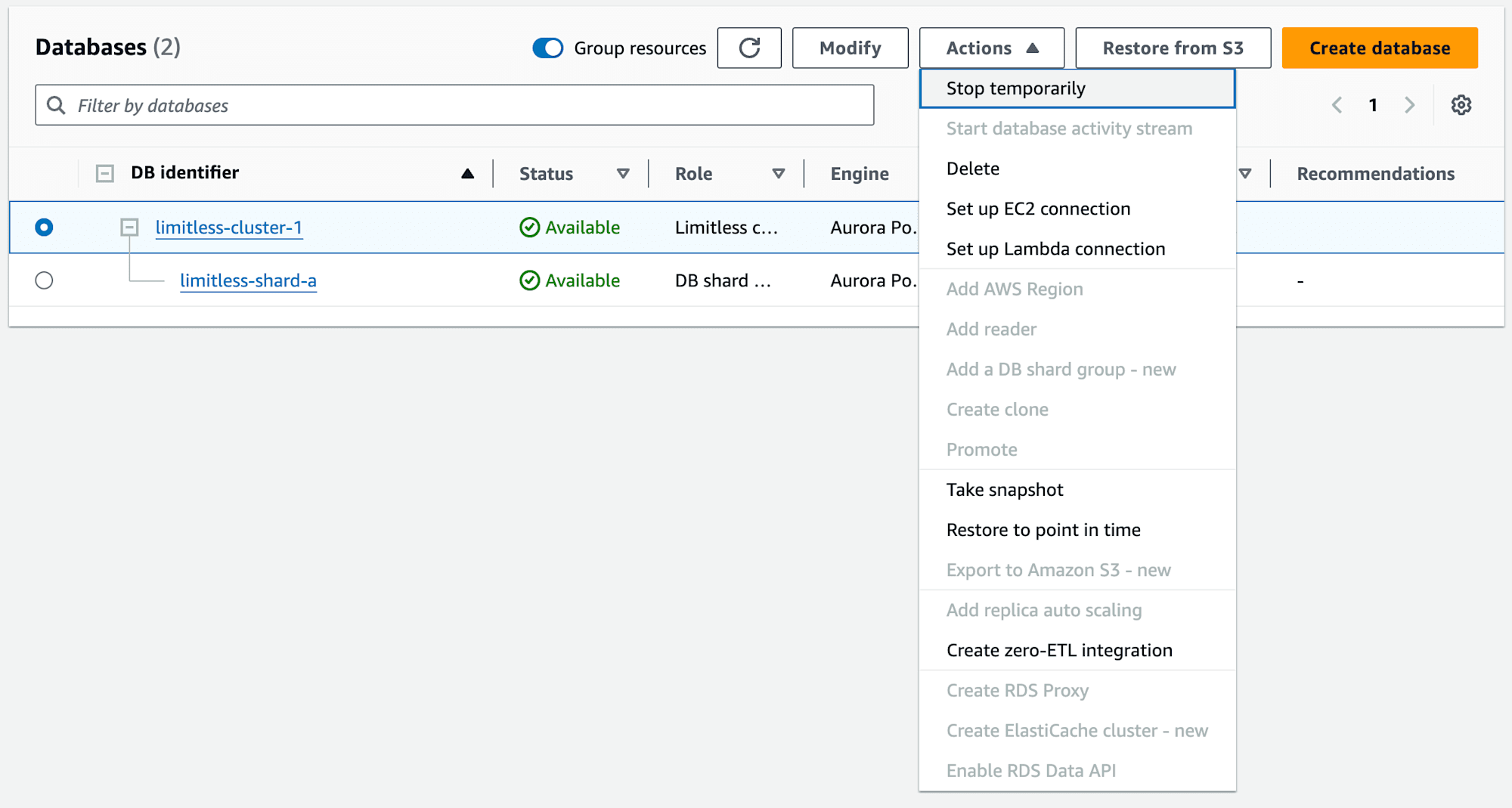
DB シャードグループのアクションは再起動と削除だけになっています。
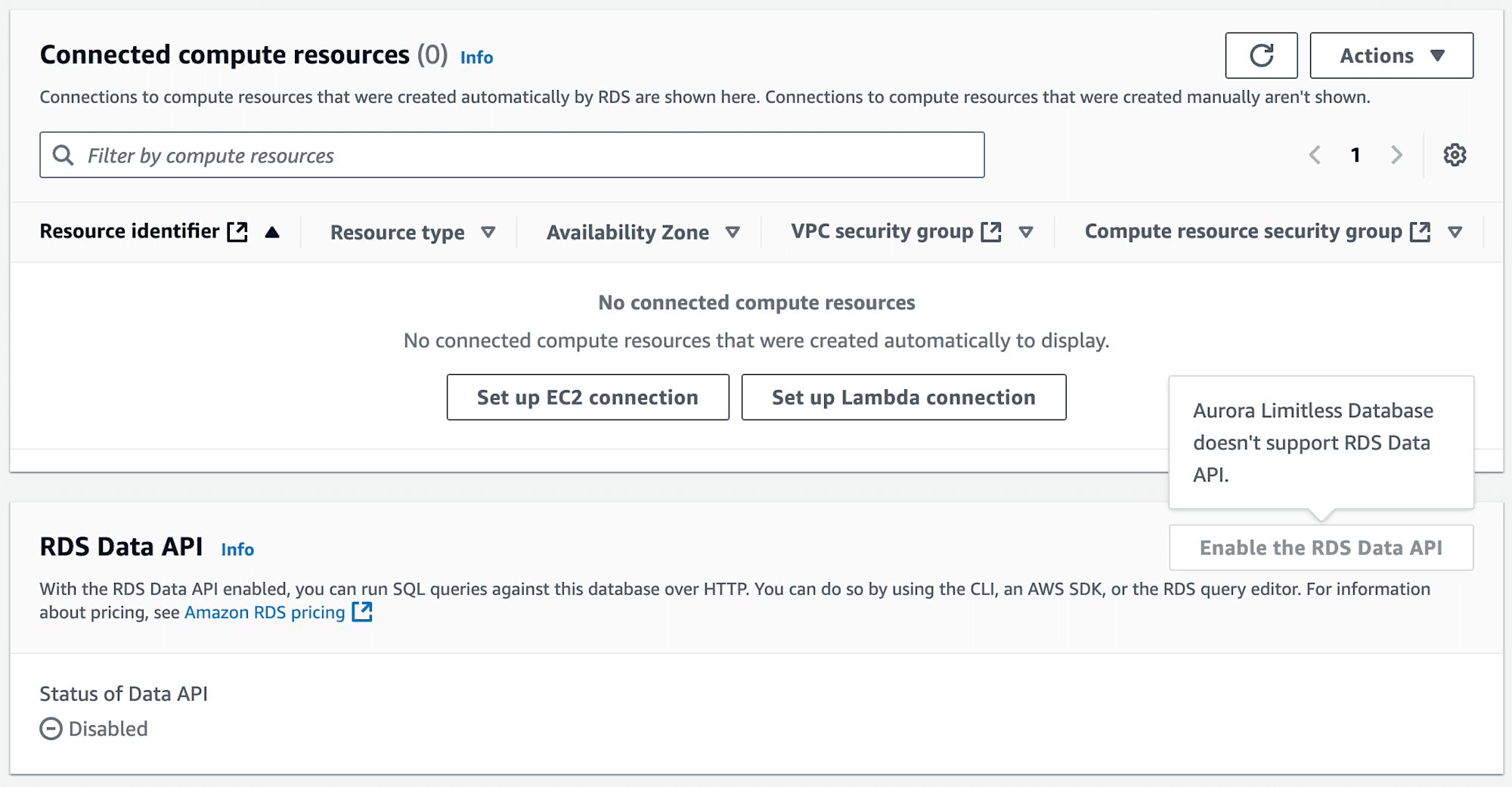
ドキュメント上に記載はありませんでしたが、RDS Data API もサポートされていないようです。
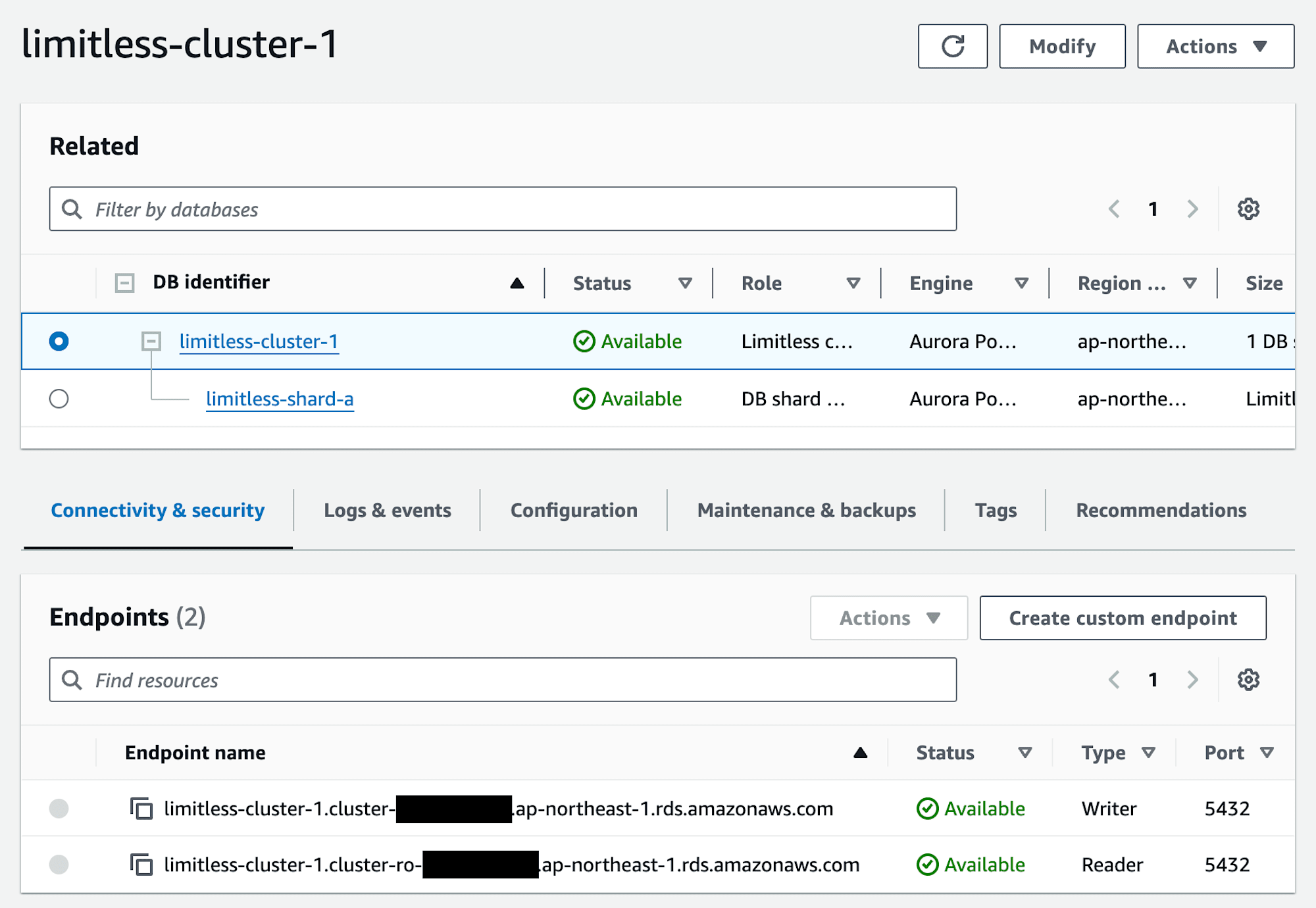
Limitless Database へのアクセス
Limitless Database へアクセスします。まずはアクセス先を確認します。
クラスターのエンドポイントを確認すると、Writer と Reader のエンドポイントが存在します。
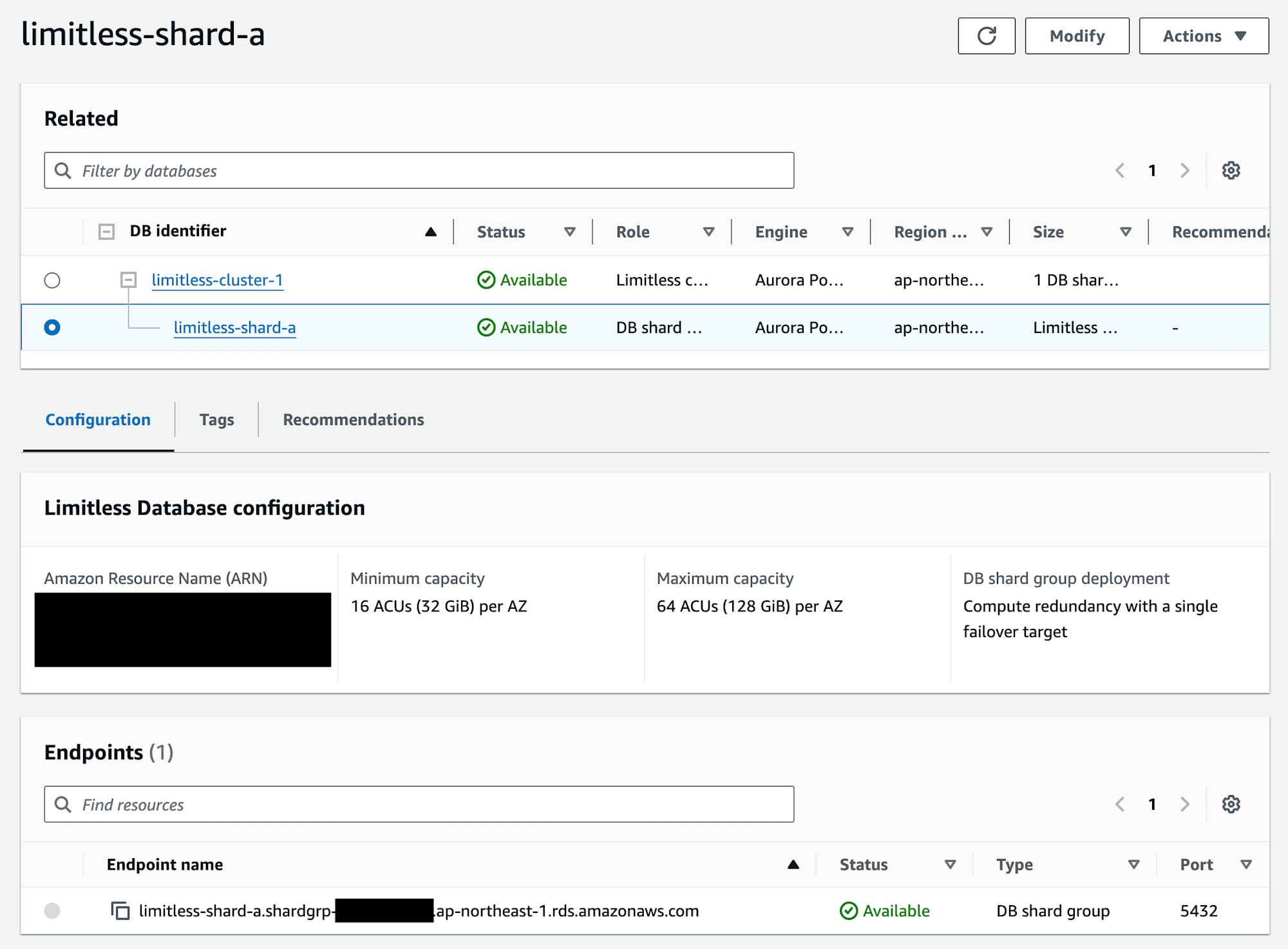
DB シャードグループでは以下の形式のエンドポイントが存在しているようです。
<DB シャードグループ名>.shardgrp-<ランダム>.<リージョンコード>.rds.amazonaws.com
各々のエンドポイントの名前解決を確認すると、以下のようになっていることが分かりました。Limitless Database では、クラスターには1つの DB シャードグループしか存在できないため、DB シャードグループ エンドポイントへアクセスしても良さそうです。
Writer エンドポイント 5 IN CNAME DB シャード グループ エンドポイント
Reader エンドポイント 5 IN CNAME DB シャード グループ エンドポイント
では Limitless Database へアクセスします。ここで使用する psql のバージョンは 16.4 です。
$ psql --version
psql (PostgreSQL) 16.4
$ psql -h limitless-shard-a.shardgrp-csflnixuc5w7.ap-northeast-1.rds.amazonaws.com -U postgres -d postgres_limitless
Password for user postgres:
psql (16.4)
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, compression: off)
Type "help" for help.
postgres_limitless=>
Limitless Database へのテーブル作成
ドキュメントの Examples using variables to create limitless tables を参考にテーブルを作成します。
item_id カラムと item_cat カラムで構成されるシャードキーを持つ、items という名前のシャードテーブルを作成します。
postgres_limitless=> BEGIN;
BEGIN
postgres_limitless=*> SET LOCAL rds_aurora.limitless_create_table_mode='sharded';
SET
postgres_limitless=*> SET LOCAL rds_aurora.limitless_create_table_shard_key='{"item_id", "item_cat"}';
SET
postgres_limitless=*> CREATE TABLE items(item_id int, item_cat varchar, val int, item text);
CREATE TABLE
postgres_limitless=*> COMMIT;
COMMIT
item_id カラムと item_cat カラムで構成されるシャードキーを持つ、item_description という名前のシャードテーブルを作成し、前の例の items テーブルと共存させます。
postgres_limitless=> BEGIN;
BEGIN
postgres_limitless=*> SET LOCAL rds_aurora.limitless_create_table_mode='sharded';
SET
postgres_limitless=*> SET LOCAL rds_aurora.limitless_create_table_shard_key='{"item_id", "item_cat"}';
SET
postgres_limitless=*> SET LOCAL rds_aurora.limitless_create_table_collocate_with='items';
SET
postgres_limitless=*> CREATE TABLE item_description(item_id int, item_cat varchar, color_id int);
CREATE TABLE
postgres_limitless=*> COMMIT;
COMMIT
colors という名前のリファレンステーブルを作成します。
postgres_limitless=> BEGIN;
BEGIN
postgres_limitless=*> SET LOCAL rds_aurora.limitless_create_table_mode='reference';
SET
postgres_limitless=*> CREATE TABLE colors(color_id int primary key, color varchar);
CREATE TABLE
postgres_limitless=*> COMMIT;
COMMIT
rds_aurora.limitless_create_table_mode セッション変数をリセットします。
postgres_limitless=> RESET rds_aurora.limitless_create_table_mode;
RESET
rds_aurora.limitless_tables ビューで Limitless Database のテーブルとそのタイプに関する情報が含まれます。
postgres_limitless=> SELECT * FROM rds_aurora.limitless_tables;
table_gid | local_oid | schema_name | table_name | table_status | table_type | distribution_key
-----------+-----------+-------------+------------------+--------------+------------+--------------------------
16003 | 17771 | public | colors | active | reference |
16002 | 17765 | public | item_description | active | sharded | HASH (item_id, item_cat)
16001 | 17750 | public | items | active | sharded | HASH (item_id, item_cat)
(3 rows)
rds_aurora.limitless_table_collocations ビューで共存テーブルに関する情報が含まれます。
postgres_limitless=> SELECT * FROM rds_aurora.limitless_table_collocations ORDER BY collocation_id;
collocation_id | schema_name | table_name
----------------+-------------+------------------
16001 | public | items
16001 | public | item_description
(2 rows)
rds_aurora.limitless_table_collocation_distributions ビューで各コロケーションのキー分布が含まれます。
postgres_limitless=> SELECT * FROM rds_aurora.limitless_table_collocation_distributions ORDER BY collocation_id, lower_bound;
collocation_id | subcluster_id | lower_bound | upper_bound
----------------+---------------+----------------------+---------------------
16001 | 5 | -9223372036854775808 | 0
16001 | 4 | 0 | 9223372036854775807
(2 rows)
Limitless Database へのデータ投入とクエリ
データを投入してクエリを発行してみます。
以下のように items テーブルにデータを投入します。
postgres_limitless=> INSERT INTO items (item_id, item_cat, val, item)
VALUES
(1, 'AAA', 101, '111'),
(2, 'BBB', 102, '222'),
(3, 'CCC', 103, '333'),
(4, 'DDD', 104, '444'),
(5, 'EEE', 101, '111'),
(6, 'FFF', 102, '222'),
(7, 'GGG', 103, '333'),
(8, 'HHH', 104, '444');
INSERT 0 8
postgres_limitless=> SELECT * FROM items;
item_id | item_cat | val | item
---------+----------+-----+--------
3 | CCC | 103 | 333
5 | EEE | 101 | 111
2 | BBB | 102 | 222
8 | HHH | 104 | 444
1 | AAA | 101 | 111
6 | FFF | 102 | 222
7 | GGG | 103 | 333
4 | DDD | 104 | 444
(8 rows)
以下のように item_description テーブルにデータを投入します。
postgres_limitless=> INSERT INTO item_description (item_id , item_cat , color_id)
VALUES
(1, 'AAA', 201),
(2, 'BBB', 201),
(3, 'CCC', 202),
(4, 'DDD', 202),
(5, 'EEE', 201),
(6, 'FFF', 201),
(7, 'GGG', 202),
(8, 'HHH', 202);
INSERT 0 8
postgres_limitless=> SELECT * FROM item_description;
item_id | item_cat | color_id
---------+----------+----------
3 | CCC | 202
5 | EEE | 201
2 | BBB | 201
8 | HHH | 202
1 | AAA | 201
6 | FFF | 201
7 | GGG | 202
4 | DDD | 202
(8 rows)
以下のように colors テーブルにデータを投入します。
postgres_limitless=> INSERT INTO colors (color_id , color)
VALUES
(201, 'WHITE'),
(202, 'BLACK');
INSERT 0 2
postgres_limitless=> SELECT * FROM colors;
color_id | color
----------+-------
201 | WHITE
202 | BLACK
(2 rows)
rds_aurora.limitless_explain_options セッション変数で shard_plans, single_shard_optimization を設定して、実行計画を見てみます。shard_plans を設定しているので、どこのシャードにデータがあるかを確認できます。またシャードキー全体を WHERE 句で指定しているため Single Shard Optimized となっています。
postgres_limitless=> SET rds_aurora.limitless_explain_options = shard_plans, single_shard_optimization;
SET
postgres_limitless=> EXPLAIN (VERBOSE, COSTS OFF) SELECT * FROM items WHERE item_id = 1 AND item_cat = 'AAA';
QUERY PLAN
------------------------------------------------------------------------------------
Foreign Scan
Output: item_id, item_cat, val, item
Remote Plans from Shard 5:
Seq Scan on public.items_ts00155 items
Output: items.item_id, items.item_cat, items.val, items.item
Filter: ((items.item_id = 1) AND ((items.item_cat)::text = 'AAA'::text))
Query Identifier: 7481820692763206803
Remote SQL: SELECT item_id,
item_cat,
val,
item
FROM public.items
WHERE ((item_id = 1) AND ((item_cat)::text = 'AAA'::text))
Query Identifier: 37372719470985300
Single Shard Optimized
(15 rows)
実際にクエリを実行しても普通にレコードが返ってきます。
postgres_limitless=*> SELECT * FROM items WHERE item_id = 1 AND item_cat = 'AAA';
item_id | item_cat | val | item
---------+----------+-----+--------
1 | AAA | 1 | 111
(1 row)
分散トランザクション
シャードをまたがったトランザクションを実行してみます。
items テーブルで WHERE item_id = 1 AND item_cat = 'AAA' の条件ではシャードが 5 になっています。
postgres_limitless=> EXPLAIN (VERBOSE, COSTS OFF) SELECT * FROM items WHERE item_id = 1 AND item_cat = 'AAA';
QUERY PLAN
------------------------------------------------------------------------------------
Foreign Scan
Output: item_id, item_cat, val, item
Remote Plans from Shard 5:
・
・
・
items テーブルで WHERE item_id = AND item_cat = 'DDD' の条件ではシャードが 4 になっています。
postgres_limitless=> EXPLAIN (VERBOSE, COSTS OFF) SELECT * FROM items WHERE item_id = 4 AND item_cat = 'DDD';
QUERY PLAN
------------------------------------------------------------------------------------
Foreign Scan
Output: item_id, item_cat, val, item
Remote Plans from Shard 4:
・
・
・
この異なるシャードにまたがったクエリを実行してみますが、問題なく実行できます。
postgres_limitless=> BEGIN;
BEGIN
postgres_limitless=*> UPDATE items SET item = '一一一' WHERE item_id = 1 AND item_cat = 'AAA';
UPDATE 1
postgres_limitless=*> UPDATE items SET item = '四四四' WHERE item_id = 4 AND item_cat = 'DDD';
UPDATE 1
postgres_limitless=*> COMMIT;
COMMIT
``
次は分散デッドロックを確認してみます。2個のトランザクション A と B で実行してみます。
トランザクション A で `item_id = 1 AND item_cat = 'AAA'` のレコードを更新します。プロンプトはすぐに戻ってきます。
```sql
-- transaction A
postgres_limitless=> BEGIN;
BEGIN
postgres_limitless=*> UPDATE items SET item = '一一一一' WHERE item_id = 1 AND item_cat = 'AAA';
UPDATE 1
トランザクション B で item_id = 4 AND item_cat = 'DDD' のレコードを更新します。プロンプトはすぐに戻ってきます。
-- transaction B
postgres_limitless=> BEGIN;
BEGIN
postgres_limitless=*> UPDATE items SET item = '二二二二' WHERE item_id = 4 AND item_cat = 'DDD';
UPDATE 1
トランザクション A でトランザクション B と同じ item_id = 4 AND item_cat = 'DDD' のレコードを更新すると、ロックが掛かり、プロンプトが返ってこず待ちになります。
-- transaction A
postgres_limitless=*> UPDATE items SET item = '三三三三' WHERE item_id = 4 AND item_cat = 'DDD';
トランザクション B でトランザクション A と同じ item_id = 1 AND item_cat = 'AAA' のレコードを更新します。プロンプトはすぐに戻ってきます。
-- transaction B
postgres_limitless=*> UPDATE items SET item = '四四四四' WHERE item_id = 1 AND item_cat = 'AAA';
UPDATE 1
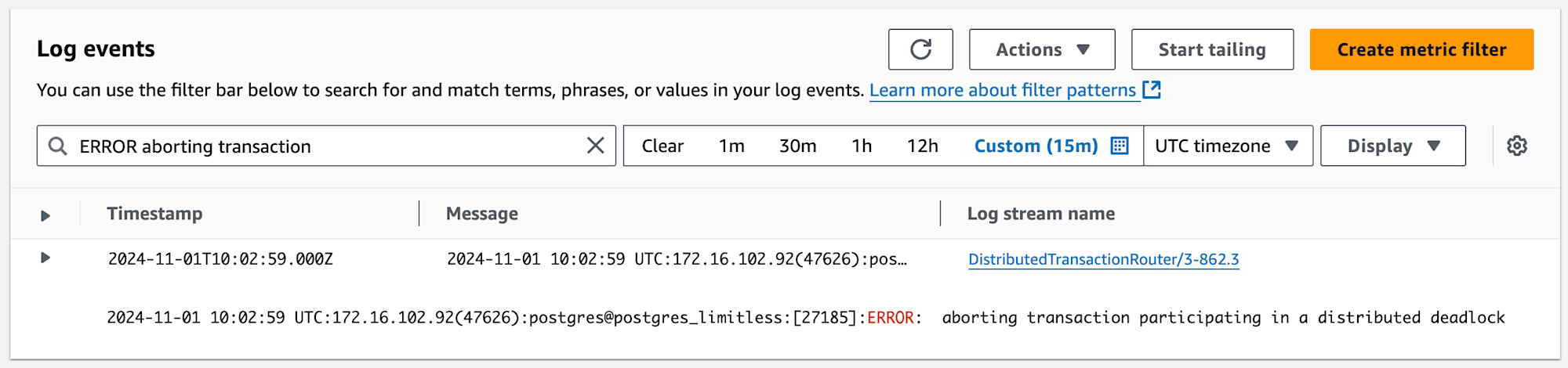
トランザクション A はプロンプトが返ってこず待ちになっていましたが、上記のトランザクション B で item_id = 1 AND item_cat = 'AAA' のレコードを更新した直後に以下のエラーを出力しました。異なるシャード間でのデッドロックを検出してロールバックされました。
ERROR: aborting transaction participating in a distributed deadlock
トランザクション A でコミットしてもロールバックされます。
postgres_limitless=!> COMMIT;
ROLLBACK
トランザクション B でコミットします。
-- transaction B
postgres_limitless=*> COMMIT;
COMMIT
更新した結果を確認すると、正常に実行できたトランザクション B の内容が反映されています。
postgres_limitless=> SELECT * FROM items WHERE item_id = 1 AND item_cat = 'AAA';
item_id | item_cat | val | item
---------+----------+-----+----------
1 | AAA | 101 | 四四四四
(1 row)
postgres_limitless=> SELECT * FROM items WHERE item_id = 4 AND item_cat = 'DDD';
item_id | item_cat | val | item
---------+----------+-----+----------
4 | DDD | 104 | 二二二二
(1 row)
発生したエラーは CloudWatch Logs にも出力されます。
最後に
昨年の AWS re:Invent 2023 からずっと待っていた Limitless Database がようやく GA となりました。Aurora のマネージドなシャード環境として NewSQL に生まれ変わりました。しかし NewSQL であるためデータが分散しているので、シャードごとのデータ配置などを意識する必要があります。1 台のインスタンスでまかなえるワークロードである限りは既存の Aurora の方が効率的に動作するし、テーブル設計も容易です。
そのため無闇矢鱈と Limitless Database を使用するのではなく、書き込みで大きなスケールの必要性が見えている場合に検討すべきものだと思います。とは言え超大規模環境では既存の Aurora では書き込み性能が不足する場合もあったので、必要に応じて採用を検討しましょう、ただしテーブル設計とクエリを十分に考慮することも合わせて実施してください。
NewSQL としての Aurora である Limitles Database は今後も検証していきたいと思いますので、続報をお楽しみに!
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/limitless-reqs-limits.html#limitless-requirements ↩︎
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/limitless-reqs-limits.html#limitless-limitations ↩︎ ↩︎
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/limitless-reference.html ↩︎
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/limitless-reqs-limits.html#limitless-not-supported ↩︎ ↩︎










